
明天,你算法了没?
关注:九三智能控,每晚学点AI算法

本项目由三部份组成,致力将英雄联盟的联赛建模为马尔可夫决策过程,之后应用加强学习来找到最佳决策,同时考虑到玩家的偏好并赶超简单的“记分板”统计。
我早已在Kaggle上提供了每位部份,便于更好地理解数据的处理方法和模型的编码形式。本文包含了前两部份,便于对我最终决定怎样建模环境的诱因进行一些说明。
第1部份:
https:///osbornep/lol-ai-model-part-1-initial-eda-and-first-mdp
第2部份:
https:///osbornep/lol-ai-model-part-2-redesign-mdp-with-gold-diff
第3部份:
https:///osbornep/lol-ai-model-part-3-final-output
这是一项正在进行中的工作,其目的仅仅是为了研究假如在游戏中引入更复杂的机器学习方式,会获得哪些样的疗效。这种方式不限于简单的摘要统计。

动机和目标
“英雄联盟”是一个以团队为单位的游戏,其中两个团队(每位团队中有5个玩家)竞争目标和杀戮。获得优势的玩家才能比她们的对手更强(获得更好的物品而且更快地升级),但是随着她们的优势降低,博得游戏的可能性也降低。为此,我们有一系列风波依赖于原本的风波,造成一个团队捣毁另一个团队并博得游戏。
像这样的序列在统计上建模并不是哪些新鲜事;多年来,研究人员早已考虑过怎样在体育运动中应用这一点,比如足球()。其中抢断,投篮和判罚等一系列动作会造成球员获得或丧失分数。
提及这一研究的目的是提供更详尽的洞察力,赶超一个简单的袋子分数(分别是足球或视频游戏中的玩家获得的分数或杀戮),并将团队的表现建模一系列在时间上连续的风波。
在例如英雄联盟等游戏中,以这些方法对风波进行建模更为重要,由于实现目标和杀戮会造成项目和级别优势。诸如,获得游戏的FirstBlood的玩家会给她们带来金币,可用于订购更强悍的物品。有了这个奖励,她们就可以显得足够强悍,进行更多的杀戮,直至她们能否率领团队取得胜利。这样的领先优势一般被称为“滚雪球”,由于球队累积获得优势,但一般赛事不是单方面的,道具和团队合作更重要。
这个项目的目标很简单:我们是否可以通过之前在游戏中发生的风波,来估算下一个最佳风波,便于按照实际的赛事统计数据来降低最终落败的可能性?
事实上,要确切的量化、衡量玩家在游戏中作出的决策是极其困难。无论搜集多少数据,计算机都无法捕捉玩家的全部信息(起码目前为止是)。比如,玩家可能在游戏中超常发挥或发挥不好,或则可能只是以她们偏好的形式玩游戏(一般由她们玩的角色类型定义)。
有些玩家自然会更具功击性而且会不断去收割“人头”,而其他玩家则会相对保守并尝试进行“推塔”。为此,我们进一步开发模型,以变玩家按照自己的表现调整玩法。
怎么让模型具备“人工智能”?
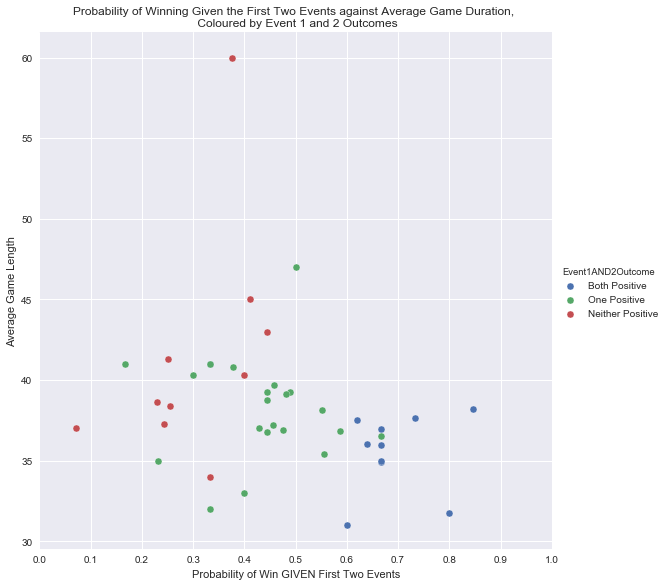
在第一部份中,我们进行了一些介绍性的统计剖析。诸如,假如团队在联赛中达成了风波1和风波2,我们就可以估算其落败的机率,如右图所示。
以下两个方面,使我们的模型不仅仅是简单的数值统计,而是真正的AI:
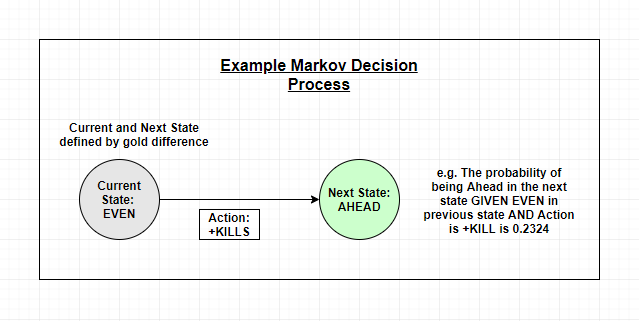
我们怎样定义马尔可夫决策过程并搜集玩家的偏好,将决定我们的模型学习和输出哪些。
预处理和马尔可夫决策
AIModelII:引入金币差别(GoldDifference)
通过初步的尝试,我们意识到,模型没有考虑负向和正向风波对后来状态的可能性的影响。换句话说,无论您在该时间点是领先还是落后,当前马卡洛夫决策过程(MDP)机率都可能发生。在游戏中,这根本不是真的;假如你落后,这么杀人数,武器和建筑等就更难获得,我们须要考虑到这一点。
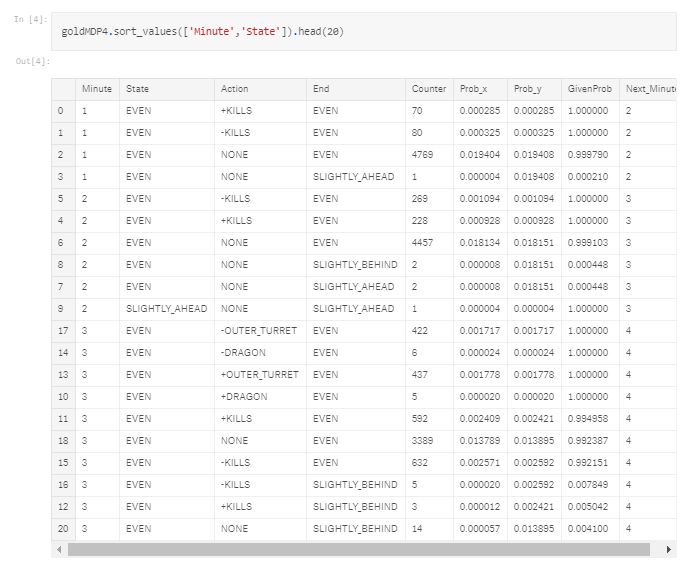
为此,我们引入团队之间的金币差别作为重新定义各状态的方法。在借助MDP过程定义状态时,除了考虑各类关键风波(杀人、获得武器等),还考虑团队在金币数目上是否领先。我们将金币的差别分类如下:
当没有感兴趣的风波发生时,我们将其定义为“NONE”事件,确保每分钟起码存在一个风波。
这个'NONE'风波代表了战队是否决定尝试拖延联赛,并帮助分辨这些在初期赛事中更好地获得金币领先而没有kill或推搭的团队。但是,这样做也大大扩充了我们的数据,由于现今早已添加了7个类别以适应可用的匹配,而且假如可以访问更多的正常匹配,这么数据量就足够了。和先前一样,我们可以通过以下方法概述每位步骤:
预处理
马尔可夫决策过程输出
模型v6版本的伪代码
我们的最终版本模型可以简单地归纳如下:
定义参数
初始化开始状态,开始风波和开始操作
选择最先发生的动,或则按照MDP过程中的可能性随机选择行动
当赛事赢或输时,结束一次迭代
跟踪在该次迭代中采取的行动和最终结果(赢/输)
使用升级的规则更新基于最终结果的操作值
重复第X次迭代
通过奖励引入偏好
首先,我们调整模型代码,便于在Return估算中包含奖励。之后,当我们运行模型时,会对个别操作引入误差,而不是简单地让奖励等于零。
在第1部份的事例中,我们展示了对行动进行正向加权的结果,之后在第2部份中,则对行动进行负向加权。
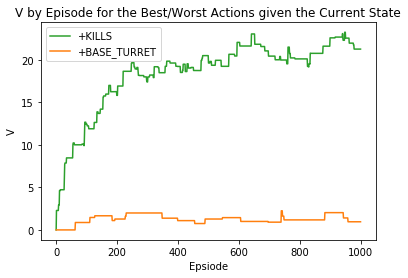
假如我们为行动提供强烈的积极奖励,则输出:'+KILLS'
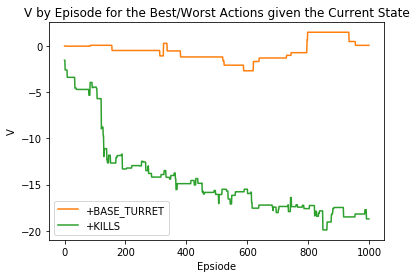
假如我们为行动提供强悍的负面奖励,则输出:'+KILLS'
更真实的玩家偏好
为此,让我们尝试近似模拟玩家的实际偏好。在这些情况下,我随机化了一些奖励以遵守这两条规则:
为此,我们对杀人数和遗失物体的奖励都是-0.05的最小值,而其他行动则在-0.05和0.05之间随机化。
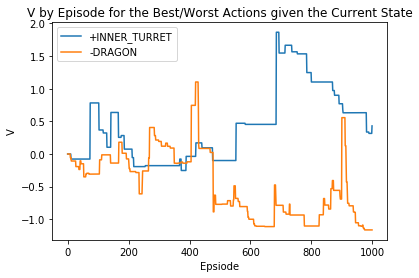
随机玩家奖励的输出
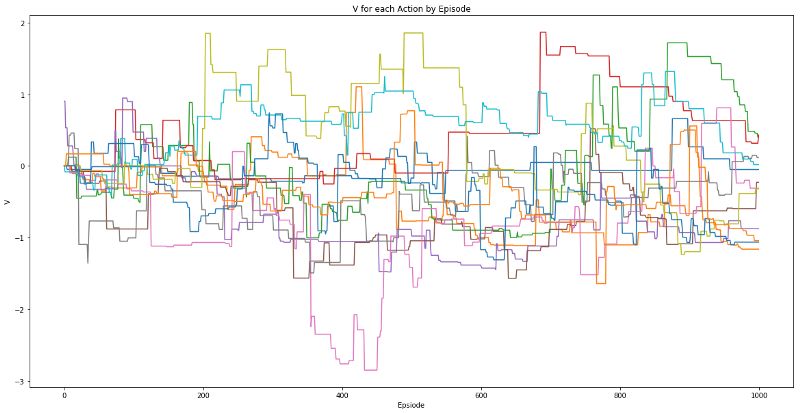
为所有操作输出随机玩家奖励
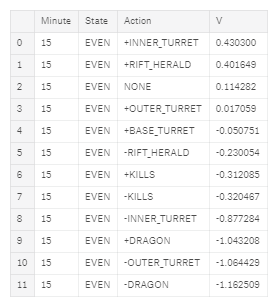
最终输出显示给定我们当前的黄金差别状态和分钟的每位动作的值
总结
我早已大大简化了一些功能(比如“杀死”并不代表实际的杀伤数目),并且数据可能难以代表正常匹配。并且,我希望这清楚地展示了一个有趣的概念,并鼓励讨论怎样进一步发展这一概念。
首先,我们将列举在施行之前须要进行的主要改进:
我们早已引入了影响模型输出的奖励,而且怎么获取呢?按照之前的研究,我们觉得最好的方式是考虑一个同时反映行为的个人疗效和团队疗效的奖励。
这显得越来越复杂,但简而言之,我们希望匹配一个玩家的决策,其中最佳的下一个决定取决于刚才发生的事情。
比如,假如球员杀害了敌军团队的所有人,这么她们可能会促使获得Baron。我们的模型早已考虑了序列中发生风波的机率,因而我们也应当以相同的方法考虑玩家的决策。
这个看法来自以下研究,该研究解释了怎样更详尽地映射反馈:
)
怎么搜集这种反馈,将决定我们的模型会取得多大成功。最终的目标是为玩家提供下一个最佳决策的实时建议。之后,在给定匹配统计数据的情况下,玩家将才能从排行最前的几个决策(按成功次序排列)中进行选择。可以通过多个游戏跟踪此玩家的选择,以进一步学习和了解玩家的偏好。这也意味着我们除了可以跟踪决策的结果,并且还可以晓得该玩家企图实现的目标(比如,企图抢占塔而是被杀害),而且会为更中级的剖析开辟信息。
这样的事情可以使玩家在较低或正常技能水平下获益颇丰,由于玩家之间的决策无法清晰地沟通。它还可以帮助辨识这些因其行为而“有毒”的球队,由于球员会通过投票系统同意联赛,之后可以看出有毒球队是否仍然忽略她们的队友,而不是依照约定计划。
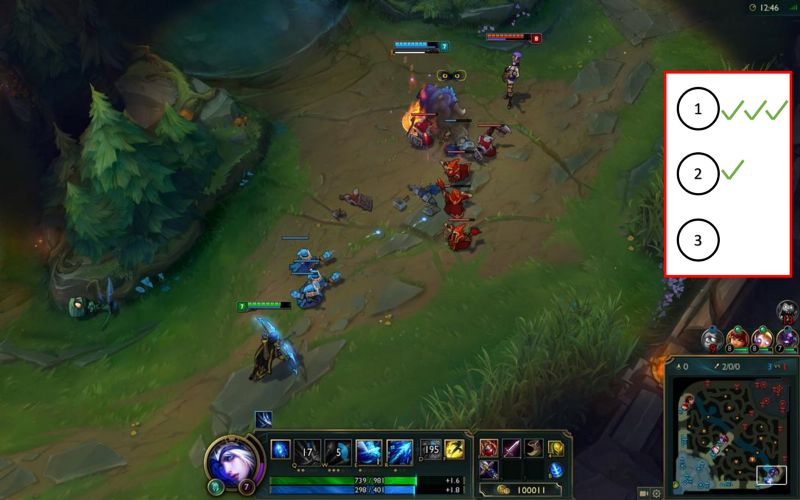
实际游戏设置中的模型推荐投票系统的示例
原文链接:
陌陌群&交流合作

版权声明
本文仅代表作者观点,不代表百度立场。
内容来源于互联网,信息真伪需自行辨别。如有侵权请联系删除。












发表评论